

方案概述
AI 運算平台是一套面向資料中心的整合式運算架構,將運算、網路、儲存存取與虛擬化/容器資源以一致的方式整合成單一、可自動化管理的系統,不僅是伺服器堆疊,更是一個可快速擴展的架構型解決方案。透過統一的高速互連架構(Unified Fabric)與無狀態(Stateless)配置思維,平台可將硬體資源配置、韌體/驅動版本管理與部署流程標準化,讓 IT 團隊以較少的人力完成大規模佈建、調整與維運,進一步降低總體擁有成本(TCO)。
在 AI/ML 工作負載上,平台可提供支援 GPU/加速器的高效能運算能力與可擴充架構,協助企業在資料準備、模型訓練到推論部署的全流程中建立穩定且高效率的基礎設施,加速 AI 價值落地並提升業務敏捷性;同時也能作為現代化應用與混合雲環境的運算底座,支撐未來擴張需求。
市場挑戰
現代企業在導入與營運 AI 運算平台時,常見的挑戰包括:
- 總體擁有成本(TCO)快速攀升
運算與網路設備大量堆疊,除了採購成本,亦帶來電力、散熱、機櫃空間與線纜管理等長期營運成本壓力。 - IT 架構分散、管理複雜度高
運算、網路、儲存往往由不同團隊以不同工具管理,造成配置不一致、變更協調困難、故障排除耗時,降低整體營運效率。 - 服務交付與環境上線速度不足
傳統部署流程繁瑣、標準化程度不足,難以快速提供開發/訓練/推論所需的算力與環境,影響業務敏捷性。 - AI 工作負載對效能與資料管線要求極高
模型訓練需要密集的 GPU/加速器算力,且常伴隨大規模資料集,對 I/O 頻寬、延遲與資料傳輸效率構成巨大挑戰。 - GPU 資源調度不易、利用率偏低
加速器資源常被固定在特定伺服器或工作站,缺乏彈性共享與排程機制,容易出現「部分機器很忙、部分閒置」的資源浪費。 - 從 PoC 到量產擴展不平滑
小規模試驗環境可行,但擴展到企業級生產規模時,容易遇到網路/儲存瓶頸、資源治理不足與管理一致性問題。 - 擴充與升級風險高、維運負擔重
隨規模成長,擴容與版本一致性管理(韌體/驅動/相依套件)變得複雜且高風險,稍有不慎就可能影響穩定性與停機風險。
方案架構說明
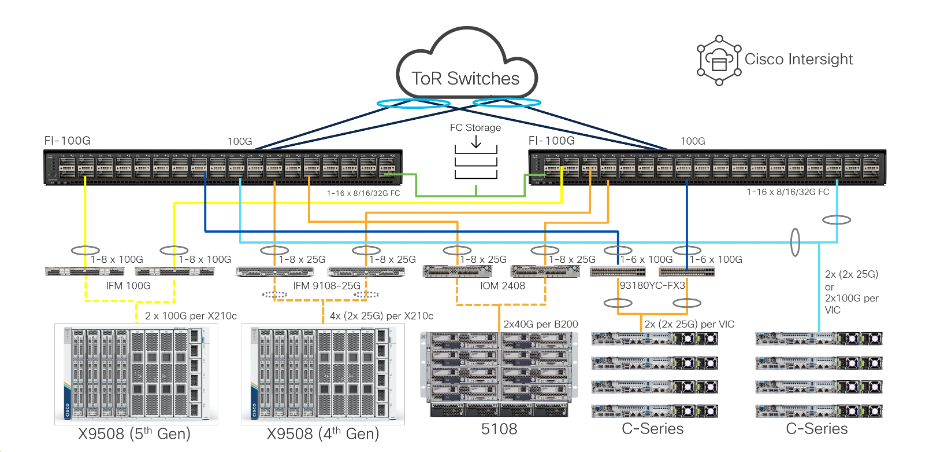
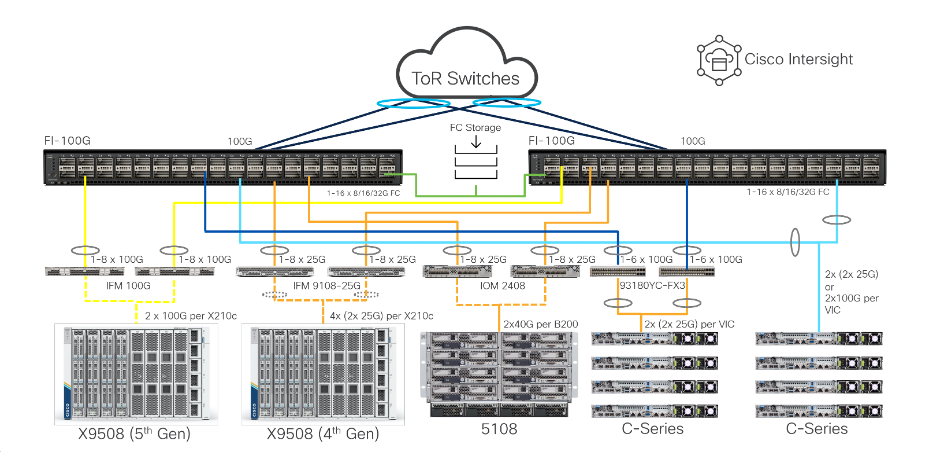
本 AI 運算平台以「整合運算+統一互連+集中管理自動化+驗證參考架構」為核心,對應 AI/ML 工作負載在算力、I/O、部署效率與規模化維運上的挑戰。
策略導向 SDN Fabric 的功能特色:
1. 整合運算資源(Unified Computing)
- 提供多樣化的運算型態(刀鋒、機架、儲存型節點、模組化系統),可依需求組合,滿足從高密度虛擬化、大數據分析到 AI 訓練/推論等不同工作負載。
- AI/ML 最佳化節點:
- 支援高密度 GPU 訓練伺服器配置(單機可搭載多張 GPU、具備大容量記憶體與高速 NVMe 介面),適合深度學習訓練與資料前處理。
- 模組化架構可依需求彈性加入 GPU 加速模組,並透過高速 PCIe/互連架構提升 GPU 擴充彈性,便於因應不同模型/專案的算力變化。
2. 統一互連架構(Unified Fabric)
- 以「單一連接與管理點」整合伺服器的 LAN 與 SAN 流量,將運算叢集與儲存存取統一於低延遲、高頻寬網路,落實「一次接線、隨需變更(Wire Once)」,有效降低線纜、交換設備與介面卡的複雜度。
- 支援高速低延遲(如 100/400Gbps 等級)的互連能力,確保分散式訓練(Distributed Training)時,多節點 GPU 之間可高效率交換資料,縮短訓練時間。
- 簡化資料湖(Data Lake)與運算叢集之間的連線與資料搬移流程,加速資料準備與特徵工程等前置作業。
3. 集中管理與自動化(Unified Management)
- 透過硬體無關的配置範本(例如服務設定檔/設定檔模板),可定義伺服器身分與組態(如 UUID/MAC/WWN、BIOS、韌體版本、I/O 配置等),並在數分鐘內套用到任一實體節點,實現「無狀態(Stateless)運算」:
- 快速佈署:建立標準化的「GPU 運算節點」模板,一鍵批量上線。
- 快速復原:硬體更換後可快速套用設定,縮短停機時間。
- 一致性維運:韌體/驅動與設定可控管,降低版本漂移風險。
- 延伸至雲端化運維平台:提供跨站點/混合雲的可視化監控、健康檢查、容量與效能分析,並可協助追蹤與最佳化 GPU 資源使用率。
- 支援 Kubernetes/容器平台生命週期管理(含佈署、升級、擴容與維護),讓 AI/ML 的訓練與推論環境能更快落地、並更易規模化。
4. 驗證參考架構(Validated Reference Architectures)
- 提供已預先測試與最佳化的 AI/ML 參考架構(運算+GPU+網路+儲存的整體堆疊設計),加速導入並降低部署風險。
- 透過參考架構的容量建議、效能基準與最佳實務,協助企業更快從 PoC 擴展到企業級量產環境,縮短規劃與驗證時間。
客戶效益
導入 AI 運算平台後,客戶可在技術與業務層面獲得具體且可衡量的效益:
1. 大幅降低總體擁有成本(TCO)
- CAPEX 降低:透過統一互連架構(Unified Fabric)整合 LAN/SAN,減少網路介面卡、儲存介面卡、交換設備與線纜數量,硬體採購成本最高可降低約 40%。
- OPEX 降低:設備與線纜簡化可同步降低電力與散熱需求,相關營運費用最高可節省約 30%。
2. 提升 IT 生產力與業務敏捷性
- 快速部署:以硬體無關的配置範本(例如服務設定檔/模板)標準化節點設定,原本需數天至數週的部署流程可縮短至分鐘級完成。
- 敏捷回應:IT 可快速調配算力資源以支援新專案與突發需求,縮短等待時間,加速業務推進。
3. 簡化維運管理、縮短復原時間(MTTR)
- 單一管理介面:集中化管理與監控數十到數百台節點的硬體、韌體、I/O 與健康狀態,降低分散式管理複雜度。
- 快速故障復原:無狀態(Stateless)配置讓故障節點可快速替換並套用既定組態,將服務復原時間由「小時級」縮短至「分鐘級」,提升可靠度。
4. 增強效能與可擴充性
- 高效能 I/O:低延遲、高頻寬互連可降低 I/O 瓶頸,強化虛擬化、資料庫與 AI 訓練等關鍵工作負載效能。
- 平滑線性擴充:從單機到叢集擴容可無縫納入同一管理域,擴展路徑可預測、部署一致性更高。
5. 加速 AI 專案落地
- 透過標準化模板與自動化工具,將 AI 基礎環境準備時間由數週縮短至數小時~數天,讓資料科學團隊更快投入模型開發、訓練與推論部署。
6. 最大化 GPU 投資報酬率(ROI)
- 以集中治理與資源調度機制提升 GPU 資源可視性與分配效率,降低閒置浪費、提升昂貴加速器資產的整體使用率。
7. 降低 AI 基礎架構導入風險
- 採用預先測試與最佳化的參考架構(運算+網路+儲存+軟體堆疊),提升相容性與效能可預期性,降低導入與擴展的不確定性。
專業服務
我們提供全方位服務,確保 SDDC(Software-Defined Data Center)順利導入與穩定運行:
- 架構規劃與設計
盤點現有環境與痛點,評估 AI 工作負載需求(GPU/儲存/網路),完成端到端架構與擴充藍圖。 - 部署與移轉服務
完成設備安裝設定,整合既有網路、儲存與虛擬化/容器平台,並提供分階段移轉與驗證。 - 維運與優化服務
定期健康檢查與效能調校,建立版本、韌體、驅動一致性與生命週期管理,降低升級風險。 - 技術支援與學習服務
提供事件處理、疑難排解與維運諮詢(可依需求提供 SLA/7×24)。並針對 IT 管理與維運團隊提供平台操作、最佳實務與故障排除訓練,提升自主管理能力。